-
From quick prototyping with LLMs to more reliable and efficient NLP solutions
At AstraZeneca’s NLP Community of Practice, I talked about how to use LLMs for fast prototyping in NLP applications, with a specific focus on mining clinical trials.

-
How to get the most out of your open-source contributions?
As I’m celebrating 10 years of contributing open-source code on Github, I share some tips & tricks on how to collaborate efficiently on a code base.

-
Integrating Large Language Models into structured NLP pipelines
In this talk presented at the Belgian NLP meetup, I showcase how to build such a structured pipeline with the open-source NLP toolbox spaCy, and its recent extension ‘spacy-llm’.

-
spaCy: A customizable NLP toolkit designed for developers
At ODSC Europe 2023, I presented the open-source NLP toolbox spaCy, and demonstrated how Large Language Models (LLMs) can be integrated into your NLP pipelines.

-
How to maximize probability of success for your Machine Learning solution?
This LinkedIn post offers some tips and tricks from personal experience, helping you get the most out of your ML/NLP projects. It’s all about data and iteration!
-
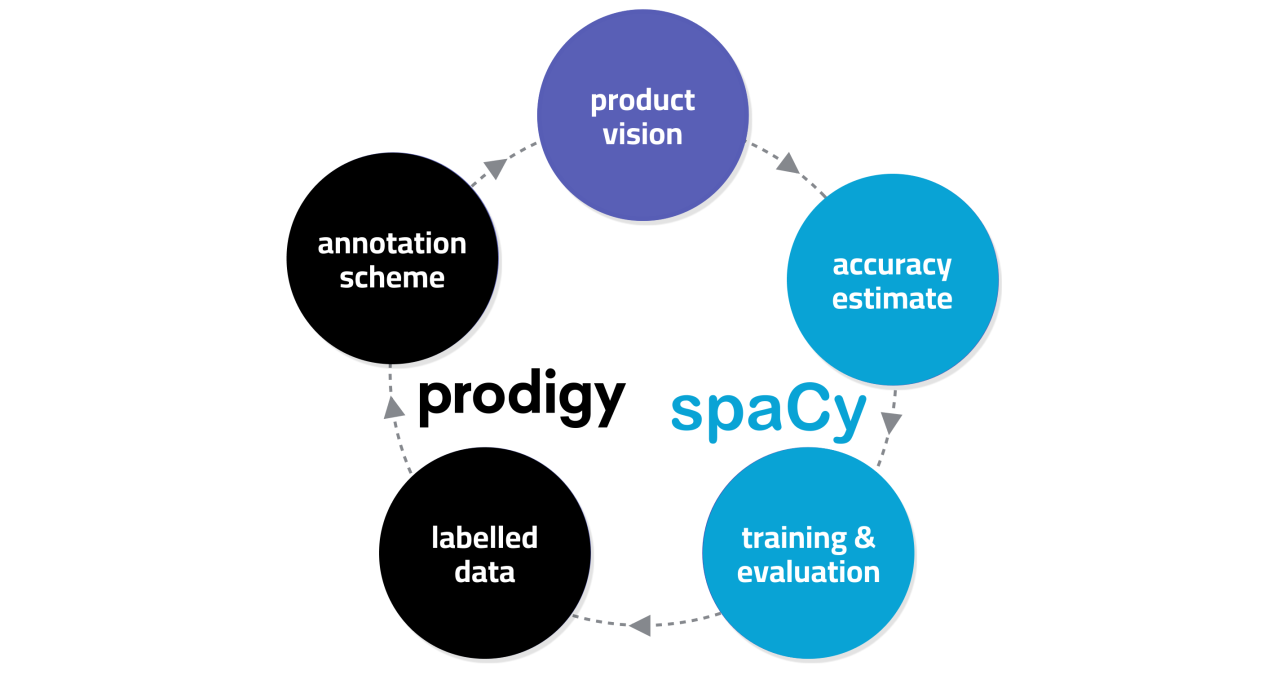
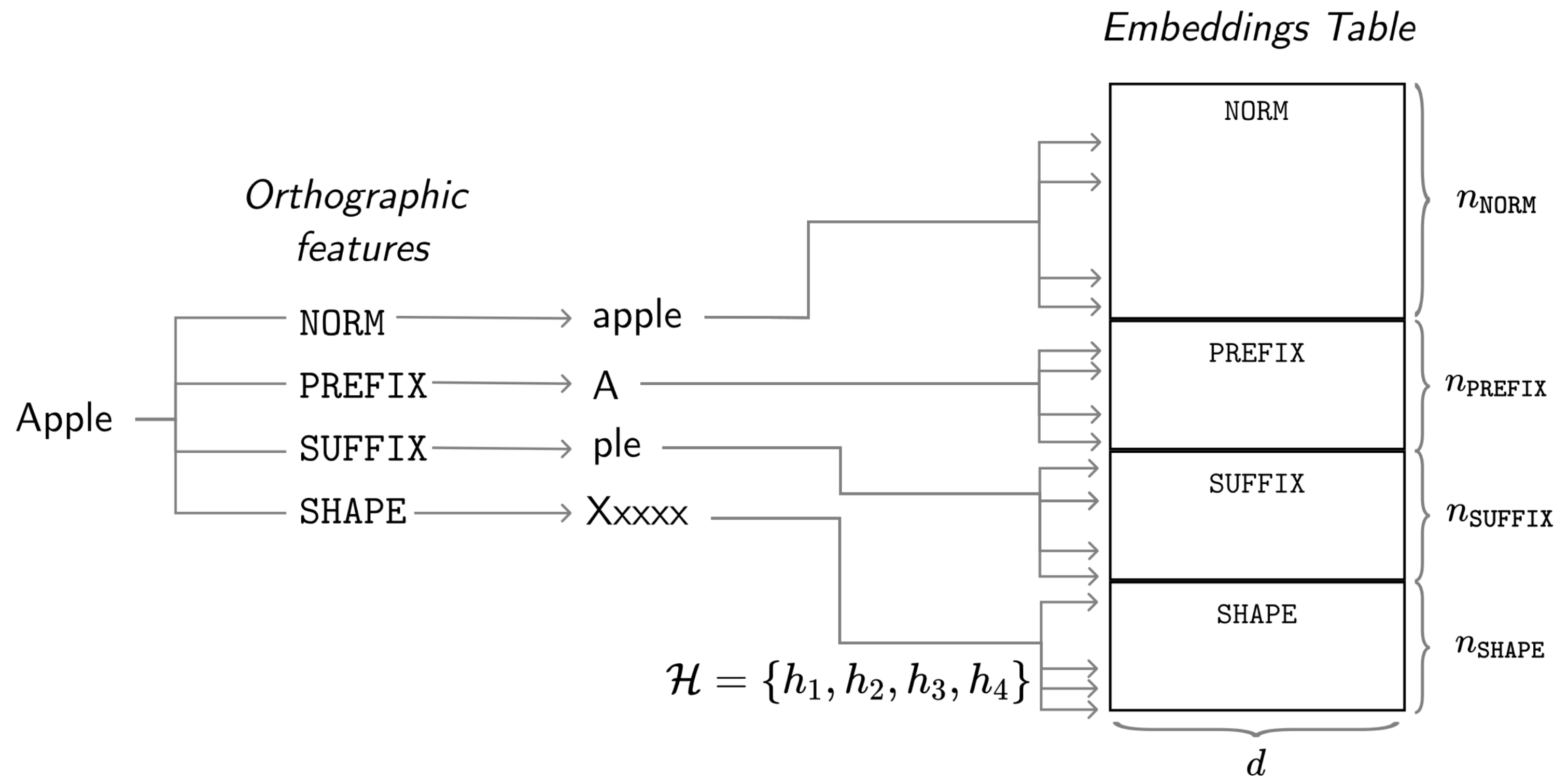
Multi hash embeddings in spaCy
In this technical report we lay out a bit of history and introduce the embedding methods in spaCy in detail. Further, we critically evaluate the hash embedding architecture with multi-embeddings on Named Entity Recognition datasets from a variety of domains and languages.
-
End-to-end Neural Coreference Resolution in spaCy
This blog post introduces a novel coreference implementation for spaCy. We’ve based our implementation on a recent incarnation of the neural paradigm published in the paper “Word-Level Coreference Resolution” by Vladimir Dobrovolskii, which was published in EMNLP 2021.

-
Spancat: a new approach for span labeling
The SpanCategorizer is a new spaCy component that answers the NLP community’s need to have structured annotation for a wide variety of labeled spans, including long phrases, non-named entities, or overlapping annotations.

-
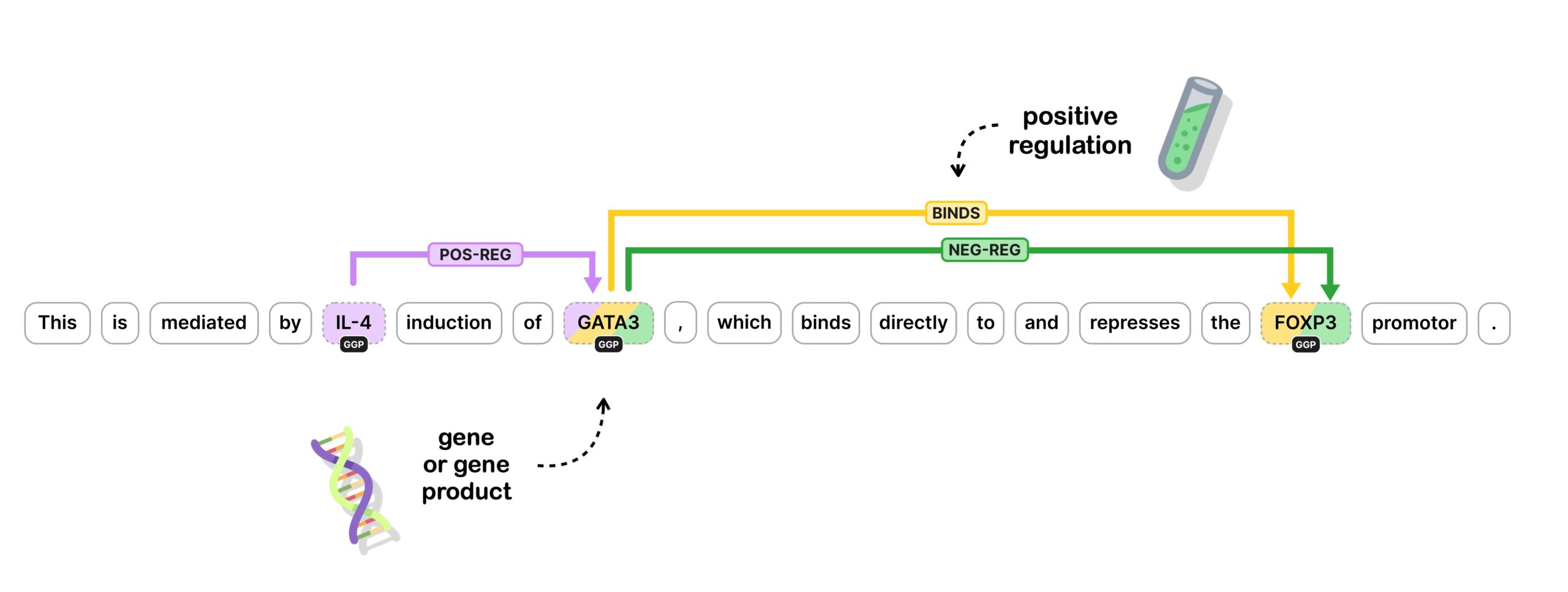
Implementing a custom trainable component for relation extraction
This video shows how to apply the new spaCy v3 features as we work our way through implementing a new custom component from scratch. The specific challenge we are setting ourselves here is implementing a custom component to predict relationships between named entities, also called relation extraction.
-
spaCy v3.0
spaCy v3.0 is a huge release! It features new transformer-based pipelines that get spaCy’s accuracy right up to the current state-of-the-art, and a new workflow system to help you take projects from prototype to production.

-
Training a custom Entity Linking model with spaCy
This video tutorial shows how to use spaCy to implement and train a custom Entity Linking model that disambiguates textual mentions to unique identifiers.

-
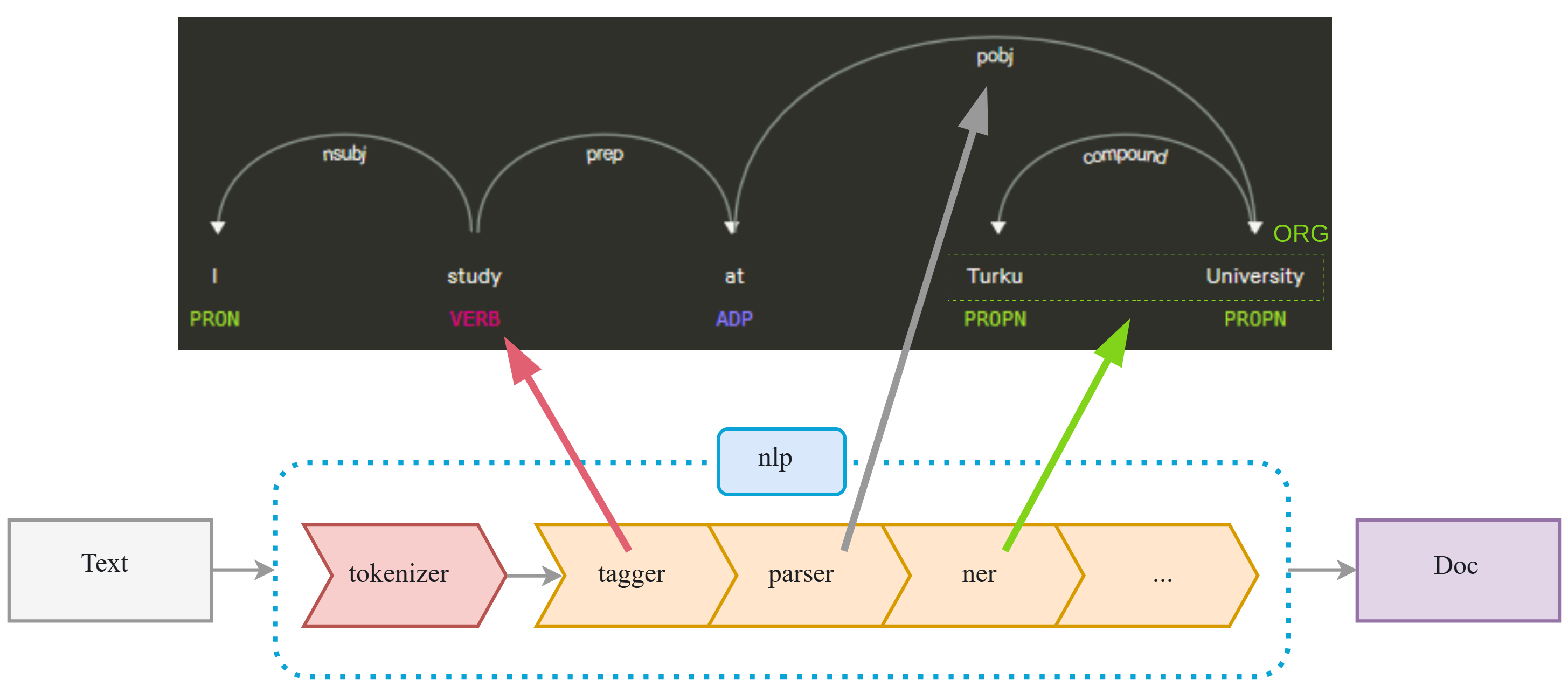
Building customizable NLP pipelines with spaCy
At a Turku.AI meetup, I gave a talk explaining spaCy’s typical usage as well as upcoming features for the v.3 release.
-
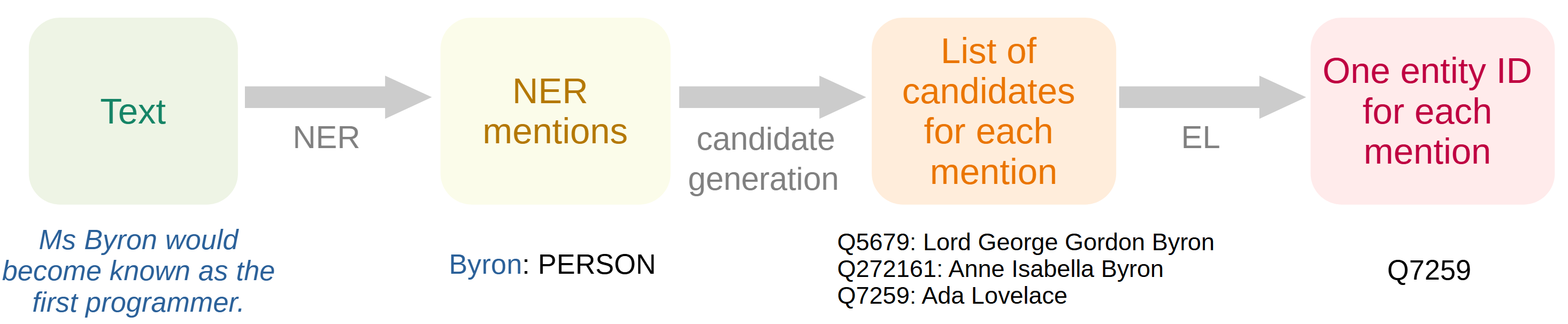
Entity linking for spaCy: Grounding textual mentions
In this talk, I present my recent work on adding Entity Linking functionality to spaCy, which allows grounding information from text into “real world” unique identifiers defined by a knowledge base (KB).
-
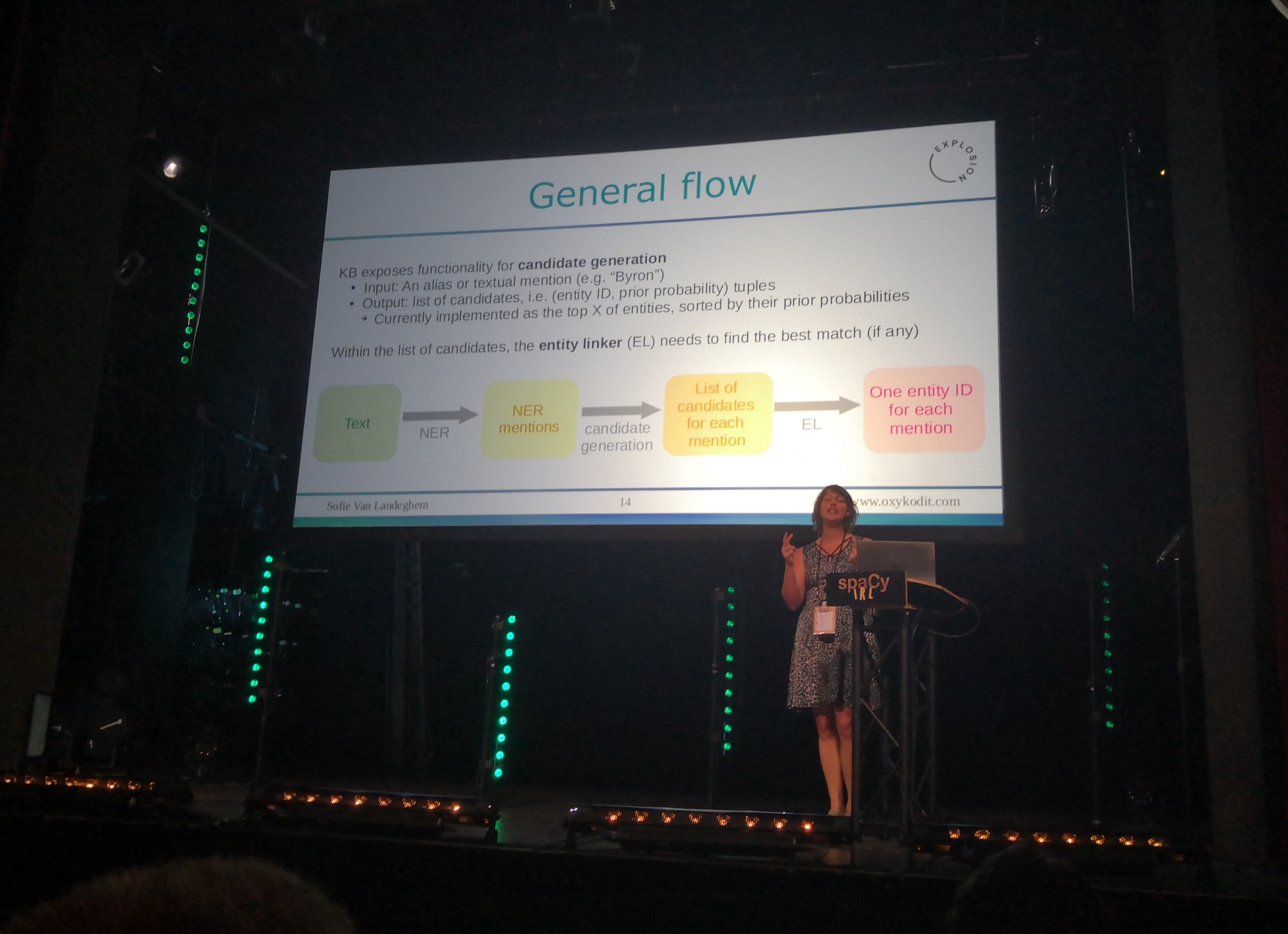
Entity linking functionality in spaCy
At spaCy IRL 2019, I presented our ongoing work on the Entity Linking functionality in spaCy, including our efforts to work with a fast and efficient in memory KB, a neural network architecture that encodes both the entity information as well as the sentence context, and the ability to add more features as we’re experimenting.
-
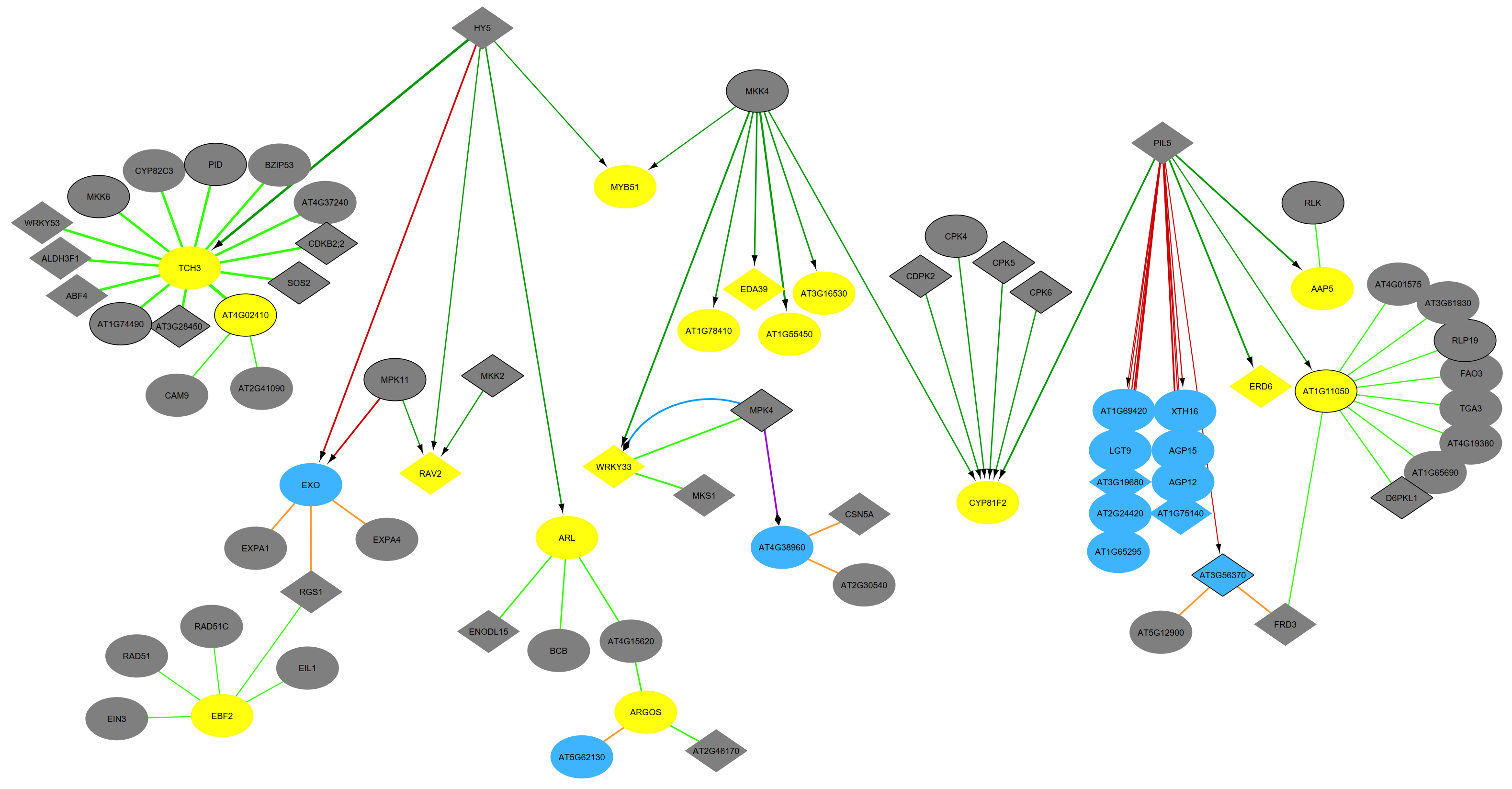
Studying the dynamic rewiring of molecular networks
At this Women in Tech event in Antwerp, I’ve given an talk showing how methods from Natural Language Processing, Data Integration and Graph Analysis all contribute to studying the dynamic rewiring of molecular networks.
-
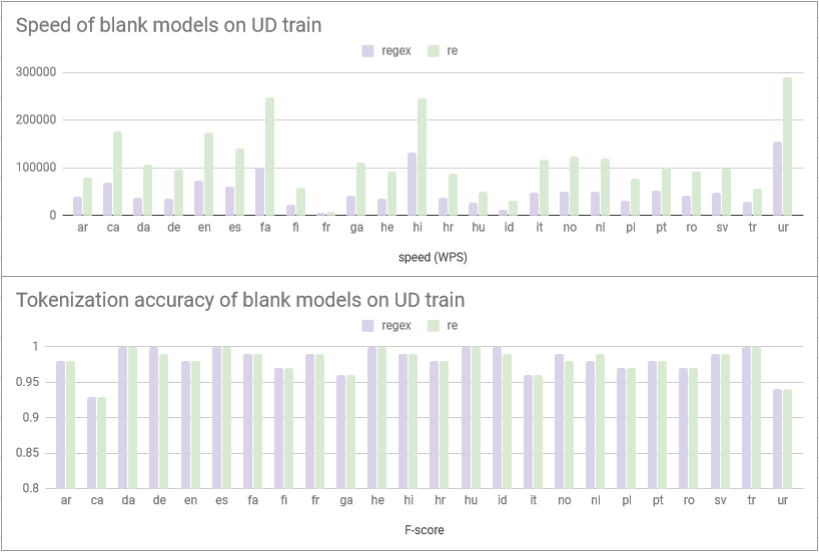
Increasing tokenization speed across spaCy’s core languages
As oe of my first core contributions to the spaCy open-source NLP library – this PR increases tokenization speed with a factor of 2-3 across all languages.
-
Developing a cocktail generator that optimizes your drink to your taste
In the past few months working at Foodpairing in Gent, I’ve been working on a revamped version of our cocktail generator. Testing the algorithms means tasting the cocktails it produces – resulting in a delicious afternoon at work!

-
TEDxBigData: Machine Learning & Natural Language Processing
I had the opportunity to present at a TEDxBigData event organized by J&J. In this talk, I shared my enthousiasm and love for Natural Language Processing by giving some examples of ambiguities in natural language, as well as showing some amazing examples of what NLP can do in concrete business cases today.

-
Cell line name recognition in support of the identification of synthetic lethality in cancer from text
In this study, we revisit the cell line name recognition task, evaluating both available systems and newly introduced methods on various resources. We further introduce two text collections manually annotated for cell line names: the broad-coverage corpus Gellus and CLL, a focused target domain corpus.
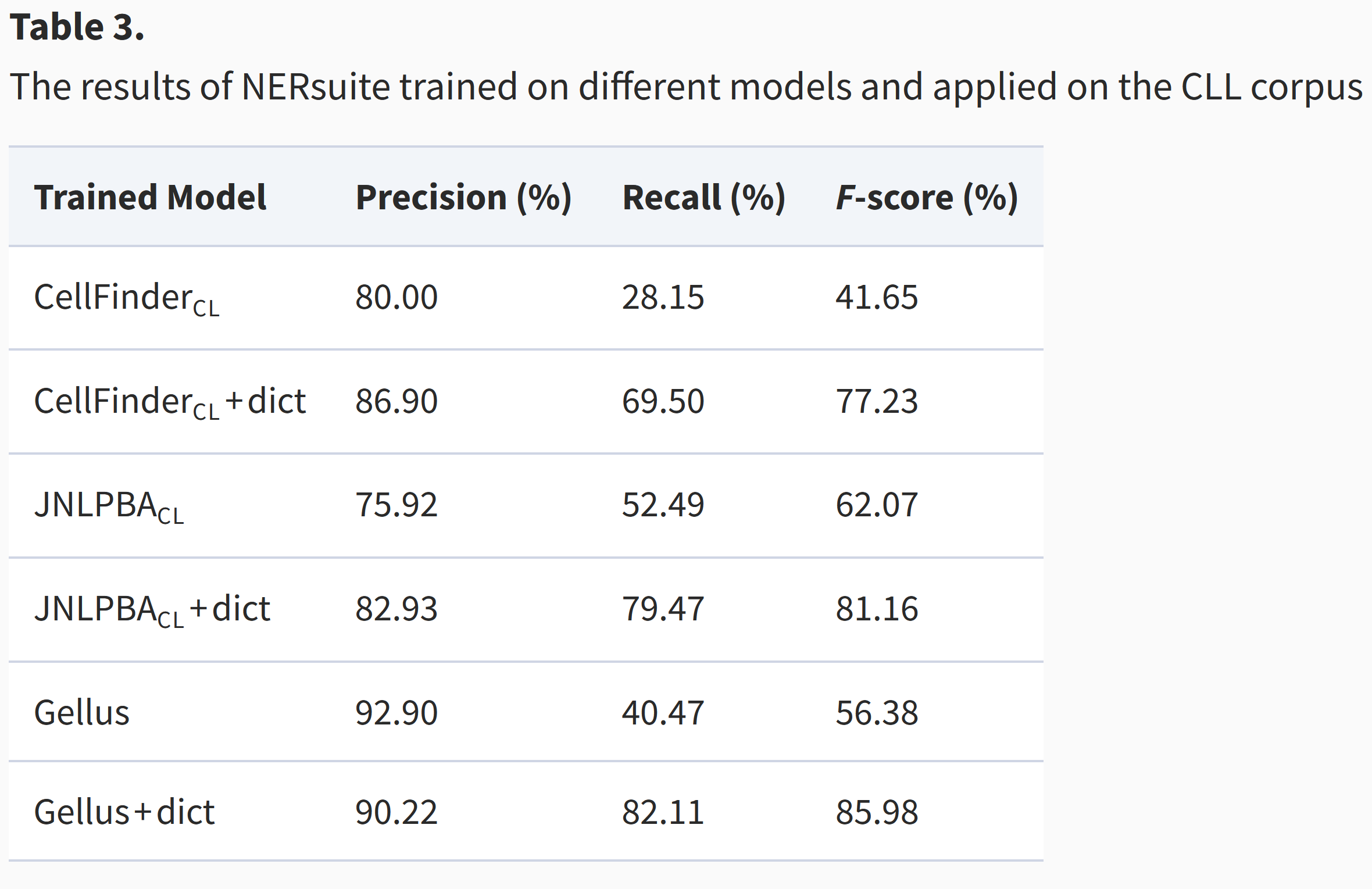
-
Diffany: an ontology-driven framework to infer, visualise and analyse differential molecular networks
In this work, we present a generic, ontology-driven framework to infer, visualise and analyse an arbitrary set of condition-specific responses against one reference network. We propose an integrative framework called “Diffany” to standardize differential networks and promote comparability between differential network studies.
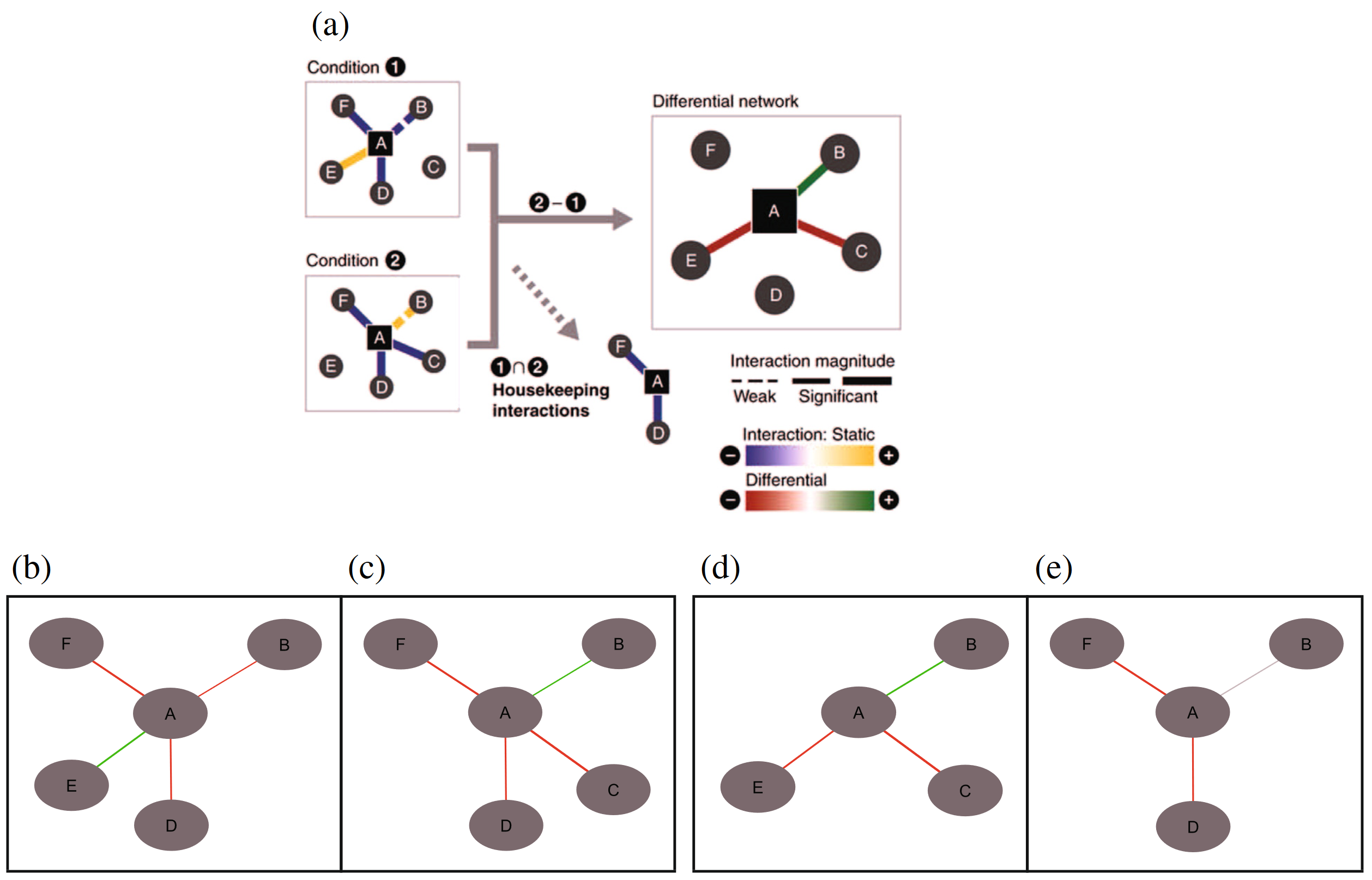
-
The KnownLeaf literature curation system
We constructed an annotation framework for the curation of the scientific literature studying the molecular mechanisms that control leaf growth and development in Arabidopsis thaliana (Arabidopsis). A total of 283 primary research articles were curated by a community of annotators, yielding 9947 relations monitored for consistency and over 12,500 references to Arabidopsis genes.

-
EVEX in ST’13: Application of a large-scale text mining resource to event extraction and network construction
In this paper, we describe our participation in the latest BioNLP Shared Task using the large-scale text mining resource EVEX. In the Genia Event Extraction (GE) task, we implemented a re-ranking approach that resulted in the first rank of the official Shared Task results.
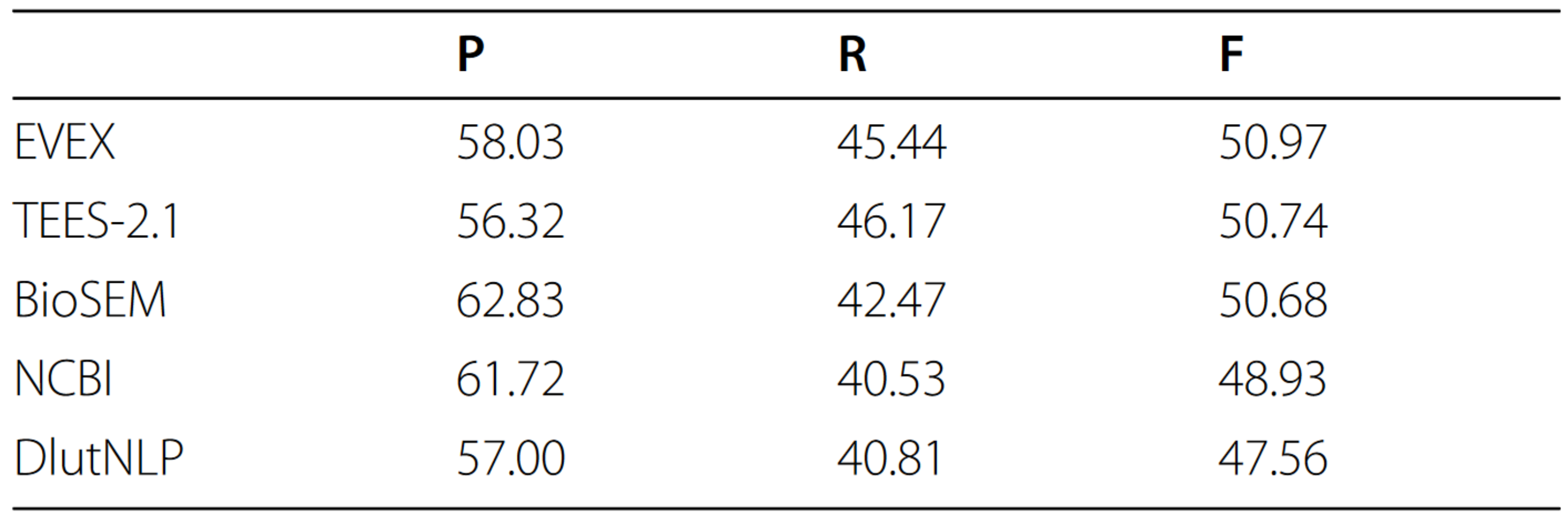
-
Large-scale event extraction from literature with multi-level gene normalization
We have combined two state-of-the-art text mining components to perform normalization and event extraction on all 1.9 million PubMed abstracts and 460 thousand PubMed Central open access full-text articles. This resource is available as the EVEX database under the CC BY-SA license.
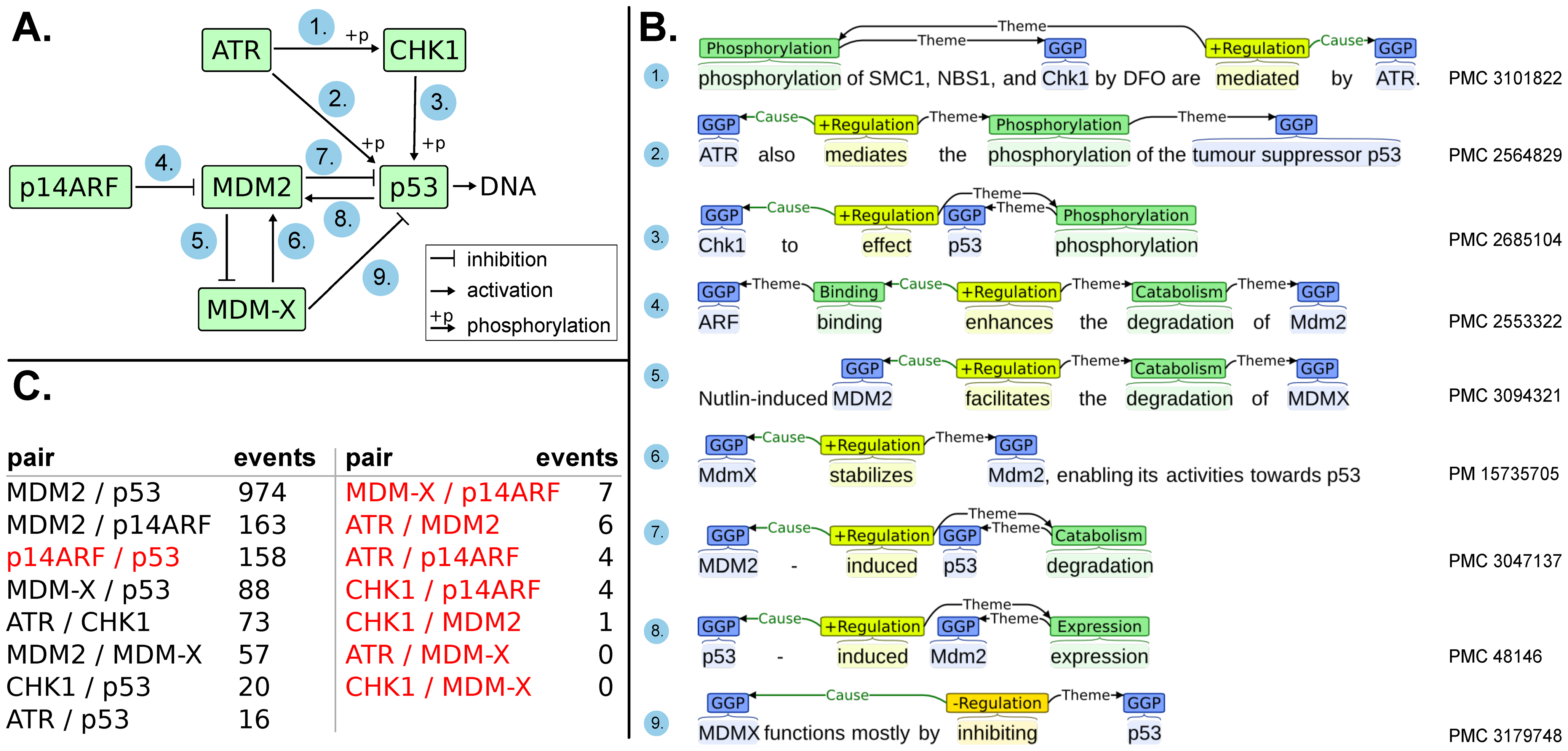
-
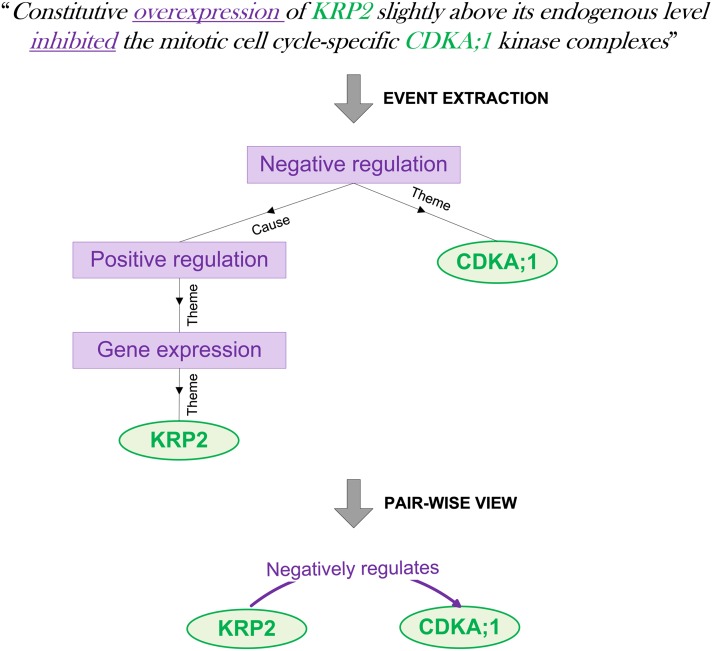
The Potential of Text Mining in Data Integration and Network Biology for Plant Research: A Case Study on Arabidopsis
In this study published in Plant Cell, we assess the potential of large-scale text mining for plant biology research in general and for network biology in particular using a state-of-the-art text mining system applied to all PubMed abstracts and PubMed Central full texts.
-
PhD thesis: Playing hide and seek on the genomic playground
My PhD thesis focuses on the field of natural language processing for biomolecular texts, or “BioNLP”. It discuss novel approaches to event extraction and the construction of a large-scale text mining resource called “EVEX”.

-
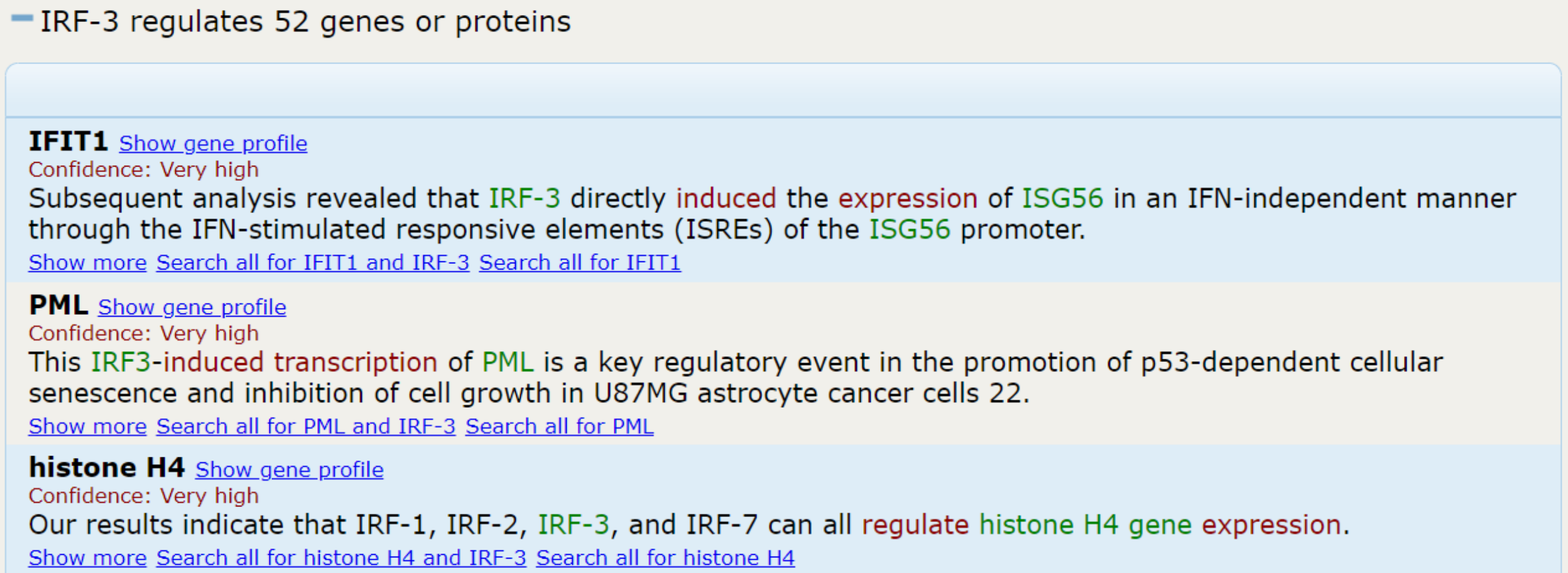
EVEX: a PubMed-scale resource for homology-based generalization of text mining predictions
Accounting for lexical variation of gene symbols, we have implemented a disambiguation algorithm that uniquely links the arguments of 11.2 million biomolecular events to well-defined gene families, providing interesting opportunities for query expansion and hypothesis generation. The resulting MySQL database, including all 19.2 million original events as well as their homology-based variants, is publicly available.
-
Discriminative and informative features for biomolecular text mining with ensemble feature selection
In this study published in Bioinformatics, we show how feature selection can be used to improve state-of-the-art text mining algorithms, while at the same time providing insight into the specific properties of the original classification algorithm.

-
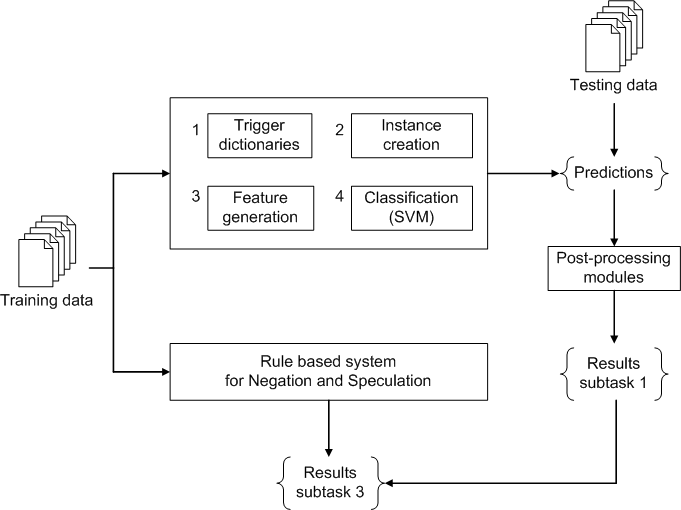
Analyzing text in search of bio-molecular events
We participated in the BioNLP Shared Task on Event Extraction with an SVM-based implementation to extract biomolecular events from text. Out of 24 participating NLP teams world-wide, we ranked 5th.
-
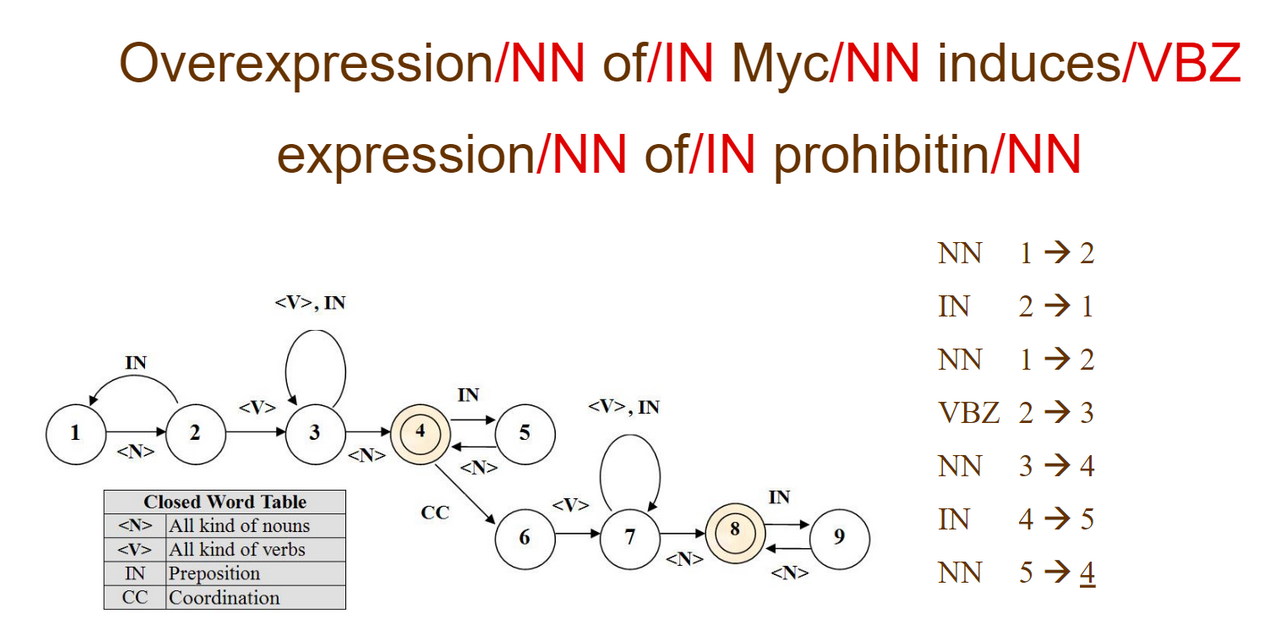
Master thesis: Automated information retrieval and data mining for bio-informatics
For my Master Thesis, I have developed GeneFetch, a system that enables biologists to easily find and browse vital information on any gene or group of genes. To this end, the system uses Text mining, Data mining and semantic web techniques.
Sofie’s Blog
 Overview
Overview