One of my first core contributions to the spaCy open-source NLP library!
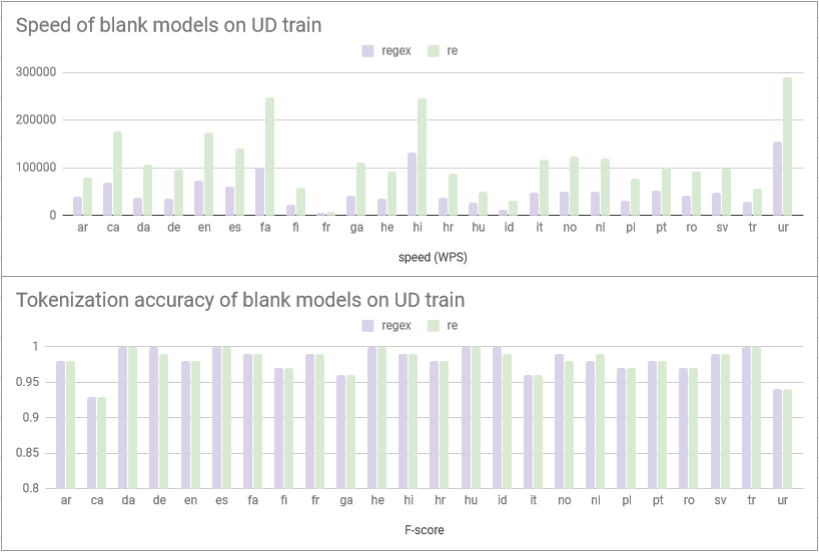
This PR increases tokenization speed by 2-3 times across languages at the same accuracy by refactoring the regular expressions and replacing `regex` with `re`.
→ Code: Github

One of my first core contributions to the spaCy open-source NLP library!
This PR increases tokenization speed by 2-3 times across languages at the same accuracy by refactoring the regular expressions and replacing `regex` with `re`.
→ Code: Github