
Background:
Modern methods for mining biomolecular interactions from literature typically make predictions based solely on the immediate textual context, in effect a single sentence. No prior work has been published on extending this context to the information automatically gathered from the whole biomedical literature. Thus, our motivation for this study is to explore whether mutually supporting evidence, aggregated across several documents can be utilized to improve the performance of the state-of-the-art event extraction systems.
In this paper, we describe our participation in the latest BioNLP Shared Task using the large-scale text mining resource EVEX. We participated in the Genia Event Extraction (GE) and Gene Regulation Network (GRN) tasks with two separate systems. In the GE task, we implemented a re-ranking approach to improve the precision of an existing event extraction system, incorporating features from the EVEX resource. In the GRN task, our system relied solely on the EVEX resource and utilized a rule-based conversion algorithm between the EVEX and GRN formats.
Results:
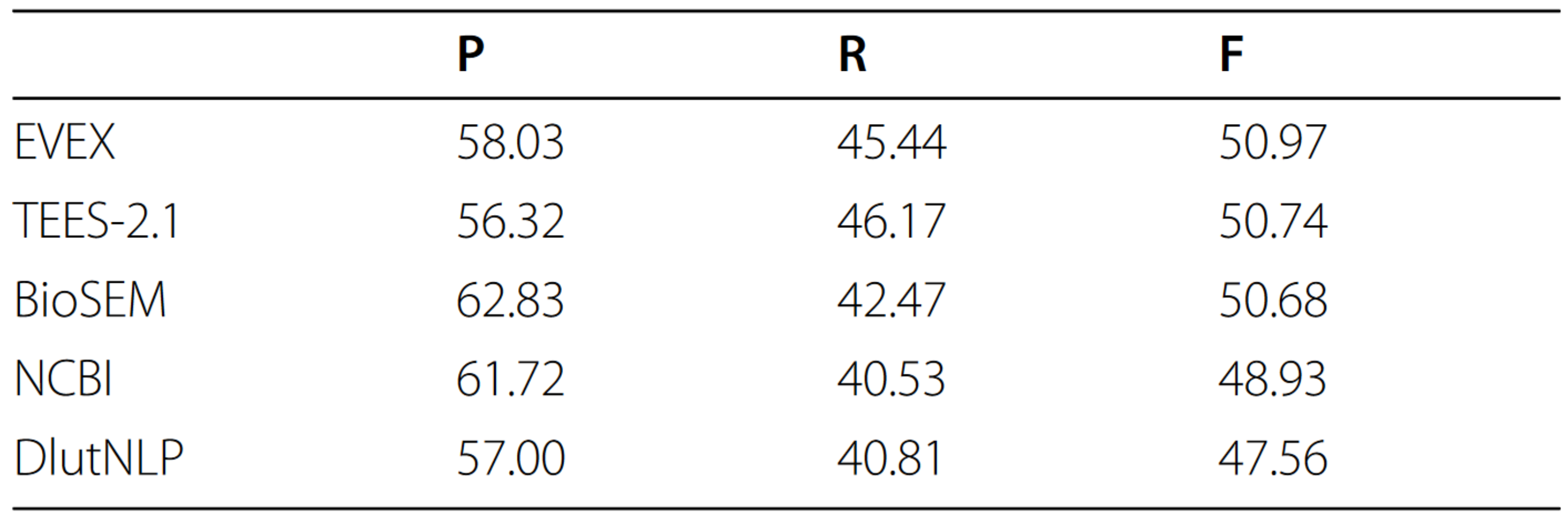
In the GE task, our re-ranking approach led to a modest performance increase and resulted in the first rank of the official Shared Task results with 50.97% F-score. Additionally, in this paper we explore and evaluate the usage of distributed vector representations for this challenge.
In the GRN task, we ranked fifth in the official results with a strict/relaxed SER score of 0.92/0.81 respectively. To try and improve upon these results, we have implemented a novel machine learning based conversion system and benchmarked its performance against the original rule-based system.
Conclusions:
For the GRN task, we were able to produce a gene regulatory network from the EVEX data, warranting the use of such generic large-scale text mining data in network biology settings. A detailed performance and error analysis provides more insight into the relatively low recall rates.
In the GE task we demonstrate that both the re-ranking approach and the word vectors can provide slight performance improvement. A manual evaluation of the re-ranking results pinpoints some of the challenges faced in applying large-scale text mining knowledge to event extraction.
→ Papers: BioNLP proceedings and BMC Bioinformatics
→ Authors: Kai Hakala, Sofie Van Landeghem, Tapio Salakoski, Yves Van de Peer, Filip Ginter