
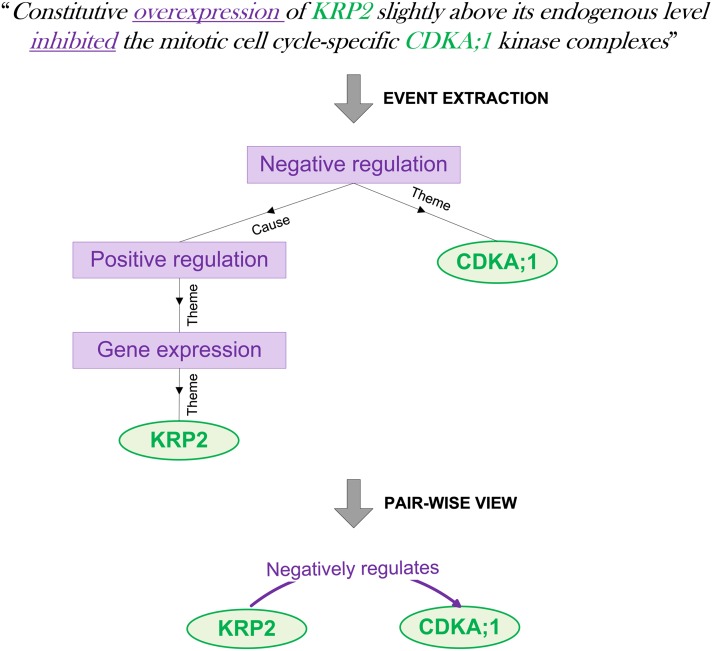
Despite the availability of various data repositories for plant research, a wealth of information currently remains hidden within the biomolecular literature. Text mining provides the necessary means to retrieve these data through automated processing of texts. However, only recently has advanced text mining methodology been implemented with sufficient computational power to process texts at a large scale.
In this study, we assess the potential of large-scale text mining for plant biology research in general and for network biology in particular using a state-of-the-art text mining system applied to all PubMed abstracts and PubMed Central full texts. We present extensive evaluation of the textual data for Arabidopsis thaliana, assessing the overall accuracy of this new resource for usage in plant network analyses. Furthermore, we combine text mining information with both protein-protein and regulatory interactions from experimental databases. Clusters of tightly connected genes are delineated from the resulting network, illustrating how such an integrative approach is essential to grasp the current knowledge available for Arabidopsis and to uncover gene information through guilt by association.
All large-scale data sets, as well as the manually curated textual data, are made publicly available, hereby stimulating the application of text mining data in future plant biology studies.
→ Paper: Plant Cell
→ Authors: Sofie Van Landeghem, Stefanie De Bodt, Zuzanna J Drebert, Dirk Inzé, Yves Van de Peer